

哈希算法在加密货币中的演变历史大致来自比特币(Bitcoin)的SHA256,到莱特币(Litecoin)的Scrypt,还有以太坊(Ethereum)的Ethash,达世币(Dash)的X11,以及后来的X13,X15,X17。
X16R是这一演变过程中的下一代算法。改变算法的目的是减少特殊硬件对采矿生态的影响。
比特币特币价值的增加,专门为并行处理设计的硬件开始显示其优势。
因此,采矿进入GPU时代。
采矿经济效益进一步提高后,使用可编程硬件在经济上变得可行,例如CPU和GPU现场可编程门阵列更具优势(FPGA),下一步是制造专门为采矿定制的芯片。
专用集成电路(ASIC)使用其他技术的采矿设备成为采矿的主人将变得不现实。
最后,随着设备的不断升级,采矿进入了更快、更高的能效比ASIC时代。
不幸的是,这种转变导致了采矿集中化的问题。
虽然任何人都可以订购这些ASIC设备,但是地理位置上更靠近生产商的人可以享受到物流时间短的好处。电力是挖矿成本的重要部分,能够获得便宜的电力是非常重要的。
中国有很多ASIC采矿机械制造商,并且可以在一些省份获得廉价的电力,这将导致采矿集中在这里。
对抗
减少ASIC矿机影响的解决方案之一是使用内存密集型哈希算法。Scrypt和ZCash使用的Equihash就是这个想法。虽然矿主使用它。ASIC矿机运算Scrypt,但相对于SHA256算法下ASIC对GPU这个优势不大。目前还没有针对Equihash的ASIC矿机出现。
另一种方法是串联各种哈希算法,一个哈希算法的输出将作为下一个哈希算法的输入。达世币(最早被称为DarkCoin),采用这种思想法X11算法。X11串联使用11种哈希算法来增加ASIC开发难度。
这种方法一度被阻止ASIC然而,目前有许多制造商在生产X11矿机算法。
与X11类似地,使用了一些其他货币X13,X15,甚至是X17,X17串联了17种哈希算法。
哈希算法的固定顺序串联仍然可以设计ASIC。串联更多的哈希算法可以增加开发ASIC的难度。像X11一样,X13、X15、X17采用固定的哈希算法串联顺序,只改变了哈希算法的数量和类型。
这种算法很可能会越来越快地突破,ASIC制造商只需要逐一实现每一种哈希算法,并根据需要组合它们。
曙光
X16R该算法通过不断打乱哈希算法的串联顺序来解决这个问题。
X16R哈希算法的选择是X15已验证的15种,加上SHA512。但16种哈希算法的串联顺序是基于前一块哈希值的动态变化。
这种动态改变顺序的做法不能使设计ASIC这是不可能的。然而,这需要ASIC更适合额外的输入。这些操作对CPU和GPU可以轻松完成。动态改变顺序的做法也可以防止ASIC制造商通过简单的扩展X11和X15生产矿机的方法X16R矿机。
X16R16种哈希算法的串联顺序由前一块哈希值的最后8字节(16进制表示的16位)决定。
哈希算法如下:
0=blake
1=bmw
2=groestl
3=jh
4=keccak
5=skein
6=luffa
7=cubehash
8=shavite
9=simd
A=echo
B=hamsi
C=fugue
D=shabal
E=whirlpool
F=sha512
例如:
前一块的哈希值为:
0000000000000000007e8a29f052ac2870045ae3970270f97da00919b8e86287
最后8字节是:0x7da00919b8e86287
每16进制位决定哈希算法,下一区块X16R哈希算法排名如下:
cubehash(7)
shabal(d)
echo(a)
blake(0)
blake(0)
simd(9)
bmw(1)
simd(9)
hamsi(b)
shavite(8)
whirlpool(e)
shavite(8)
luffa(6)
groestl(2)
shavite(8)
cubehash(7)
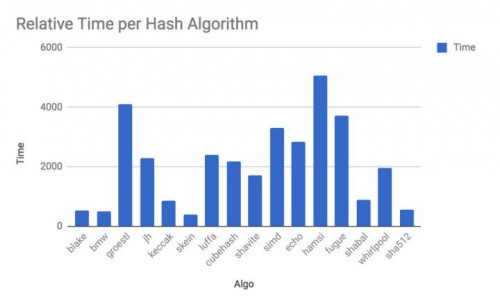
一些哈希算法比其他哈希算法需要更长的计算时间,如上表所示。
新手在计算时间差异时,会通过算法的随机搭配来平均挖掘区块。
启示
X16R该算法的测试平台是渡鸦币(Ravencoin),渡鸦币于2018年1月3日在比特币发布9周年开始。渡鸦币是X16R参考实现定义了哈希算法的数量、类型、顺序和字节,以确定哈希算法的顺序。
渡鸦币在比特币的基础上修改了发行规则、区块时间和PoW算法。
X16R可以扩展到包括Scrypt、Equihash和其他ASIC抵抗算法,以确保允许任何人使用现成的空闲计算机进行采矿。对于每种加密货币,哈希算法的顺序、类型和数量都很容易改变,以防止ASIC厂商像X11同样的算法,可以挖掘一种加密货币的矿机。
思考
为什么X16R这种动态改变哈希算法顺序的做法可以抵抗ASIC呢?
我们前面提到过,X11这种依靠堆算法数量的做法最终被ASIC因为只要货币价格足够高,制造商就会投入人力物力逐一使用11种哈希算法ASIC实现,最后组合。
在运行过程中,每个哈希算法模块都可以在装配线上运行。每时每刻,芯片利用率都可以达到100%,就像下一步一样。
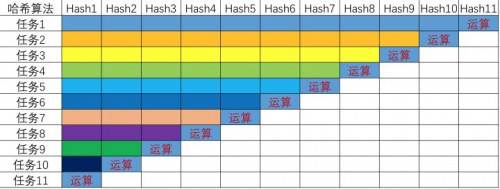
哈希算法11种X11来说,ASIC可提供11种哈希函数的电路,每时每刻都在工作,同时处理11个任务的不同部分。
而X16R在每个区块进行PoW在计算中,增加了许多挑战:
每个哈希算法被调用的次数不确定
哈希函数的排名不确定
新手预先设计了什么指标?ASIC矿机来说,一旦芯片流片,包含了多少种哈希函数,每种哈希函数有多少计算资源就是确定的。
对X16R因为前一块Hash值的后8字节,可以认为是完全随机的,我们可以计算每个块,哈希函数的类数和概率如下:
涉及哈希函数类型 概率 1 8.673617379884035e-19 2 4.263126310299903e-13 3 1.3008292880367645e-09 4 4.0680219586149147e-07 5 3.114800294252984e-05 6 0.0008548354163772504 7 0.010257933523243057 8 0.060249156768226245 9 0.1847133772998888 10 0.30522511853905976 11 0.273508450268678 12 0.13029987021900835 13 0.03130843802212624 14 0.0034140224047796153 15 0.00013610720550616406 16 1.1342267125513672e-06
在加权平均下,每个区块的平均运算10.3如果每个哈希函数的硬件实现所需的芯片面积相同,则芯片利用率约为64.4%,这是平均利用率的上限,也就是说,芯片上大约有36%的电路被浪费了。
同时,由于运算中使用每个哈希函数的次数和顺序不确定,因此更难设计出高效的装配线。
要想更好地提高流水线的并行性,必须有更多冗余的操作单元,芯片利用率更低。
要想提高芯片利用率,必然会加剧资源竞争,降低并行性,影响性能。
当货币价格足够高时,这一切只会增加难度,ASIC还是获得一定的优势。
然而,只要相对于GPU,这种优势不是很大,有助于减少算力集中的趋势。
集成电路实际上是由晶体管组成的多个门电路,门电路通过组合实现各种功能。
有没有人认为,如果有一个设备,它可以根据需要动态地结合这些门电路来实现各种功能,你不能一直充分利用整个芯片吗?
FPGA属于这种器件。
X16R虽然可以抵抗ASIC,但是对FPGA几乎无能为力。每当产生最后一个块时,就会确定下一个块使用的哈希函数类型和每个哈希函数调用的次数。
FPGA可快速重新编程,为每个哈希函数分配门数,充分利用芯片资源进行操作。



